Stat-Ease Blog

Categories
Cutting-Edge Tools in Design-Expert Version 13
Version 13 of Design-Expert® software (DX13) provides a substantial step up on ease of use and statistical power for design of experiments (DOE). As detailed below, it lays out an array of valuable upgrades for experimenters and industrial statisticians. See DX13’s amazing features for yourself via our free, fully functional, trial download at www.statease.com/trial/.
Modify Design Space Wizard

Quite often an experiment leads to promising results that lie just beyond its boundaries. DX13 paves the way via its new wizard for modifying your design space. Press the Augment Design button, select “Modify design space” and off you go. Run through the “Modify Design Space – Reactive Extrusion” tutorial, available via program Help, to see how wonderfully this new wizard works. As diagrammed on its initial screen, the modify-design-space tool facilitates shrinking and moving your space, not just expanding it. And it works on mixture as well as process space.
Poisson regression
For assessing measures that come by counts, Poisson regression models fit with greater precision than ordinary methods. Demonstrate this via the “Poisson Regression – Antiseptic” tutorial where Poisson regression proves to be just the right tool for modeling colony forming units (CFU) in a cell culture. This new modeling tool, along with logistic regression for binary responses (introduced in version 12), puts Design-Expert at a very high level for a DOE-dedicated program.
Multiple analyses per individual response

Easily model any response in various ways to readily compare them. Then chose the model most fitting for achieving optimization goals. Simply press the plus [+] button on the Analysis branch. The Antiseptic tutorial demonstrates the utility of trying several modeling alternatives, none of which can do better than Poisson regression (but worth a try!).
Rounding factor or component settings
Optimal (custom) designs work wonderfully well for laying out statistically ideal experiments. However, the numerical levels they produce often extend to an inconvenient number of decimal places. No worries: DX13 provides a new “Round Columns” button—very convenient for central composite and optimal designs. As demonstrated in the Antiseptic tutorial, this works especially well for mixture components—maintaining their proper total while making the recipe far easier for the experimenter to accomplish. Do so either on the basis of significant digits (as shown) or by decimal places.
Import Data
DX13 makes it far easier to bring in existing data. Simply paste in your data from a spreadsheet (or another statistical program) and identify each column as an input or output. If you paste in headers, right click rows to identify names and units of measure. For example, DX13 enables entry of the well-known Longley data (see the “Historical Data – Unemployment” tutorial for background) directly from an Excel spreadsheet. Easy! Once in Design-Expert, its advanced tools for design evaluation, modeling and graphics can be put to good use.
More Enhancements
Design
- The Constraints node now allows you to modify existing limits: Second thoughts? No problem!
- New ribbon with easy access to versatile design-layout features such as Change View, and Hide/Show Columns
- Runs outside the constraints flagged, but still usable for analysis; furthermore, they can be moved back into the valid space via the right-click menu
- Adding verification runs after an analysis no longer invalidates it
- Continuous and discrete numeric factors now indicated in the Design Summary
Analysis
- Response name now included when copying equations to Excel
- Pearson, Deviance, and Hosmer-Lemeshow goodness-of-it tests added for logistic regression
Diagnostics
- New preference for the default layout of the Diagnostics tabs
Graphs
- Box (and whiskers) Plot for Graph Columns: Another very useful tool for data exploration prior to analysis.
- Control multiple graphs at the same time with the factors tool: Side-by-side interactive views—enlightening!
- Perturbation and trace plots now colored by factor
- New All-Factor graphs option shows only factors selected for the model
- When the number of tick-marks becomes large, only a subset is shown
- For large designs, the Leverage graph scales to maximum value, rather than 1
- When FDS-graph crosshair goes above 80% it changes to black, rather than red
Christmas Trees on my Effects Plot?
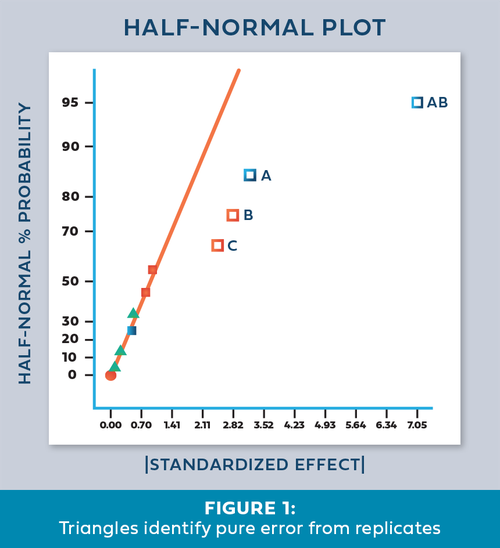
As a Stat-Ease statistical consultant, I am often asked, “What are the green triangles (Christmas trees) on my half-normal plot of effects?”
Factorial design analysis utilizes a half-normal probability plot to identify the largest effects to model, leaving the remaining small effects to provide an error estimate. Green triangles appear when you have included replicates in the design, often at the center point. Unlike the orange and blue squares, which are factor effect estimates, the green triangles are noise effect estimates, or “pure error”. The green triangles represent the amount of variation in the replicates, with the number of triangles corresponding to the degrees of freedom (df) from the replicates. For example, five center points would have four df, hence four triangles appear. The triangles are positioned within the factor effects to reflect the relative size of the noise effect. Ideally, the green triangles will land in the lower left corner, near zero. (See Figure 1). In this position, they are combined with the smallest (insignificant) effects and help position the red line. Factor effects that jump off that line to the right are most likely significant. Consider the triangles as an extra piece of information that increases your ability to find significant effects.
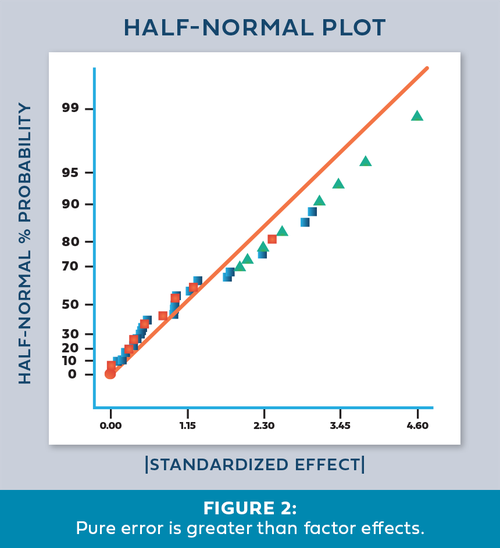
Once in a while we encounter an effects plot that looks like Figure 2. “What does it mean when the green triangles are out of place - on the upper right side instead of the lower left?”
This indicates that the variation between the replicates is greater than the largest factor effects! Since this error is part of the normal process variation, you cannot say that any of the factor effects are statistically significant. At this point you should first check the replicate data to make sure it was both measured and recorded correctly. Then, carefully consider the sources of process variation to determine how the variation could be reduced. For a situation like this, either reduce the noise or increase the factor ranges. This generates larger signals that allow you to discover the significant effects.
- Shari Kraber
For statistical details, read “Use of Replication in Almost Unreplicated Factorials” by Larntz and Whitcomb.
For more frequently asked questions, sign up for Mark’s bi-monthly e-mail, The DOE FAQ Alert.
Breaking beyond A/B splits for better business experiments
Design of experiments (DOE), being such an effective combination of multifactor testing with statistical tools, hits the spot for engineers and scientists doing industrial R&D. However, as documented in my white paper on Achieving Breakthroughs in Non-Manufacturing Processes via Design of Experiments (DOE), this statistical methodology works equally well for business processes. Yet, non-manufacturing experimenters rarely make it beyond simple one-factor-at-a-time (OFAT) comparisons known as A/B splits—most recently embraced, to my great disappointment, by Harvard Business Review*. But to give HBR some credit, this 2017 feature on experimentation at least mentions “multivariate” (I prefer “multifactor”) testing as a better alternative.
To see an illuminating example of multifactor testing applied to marketing, see my April 21 StatsMadeEasy blog: Business community discovers that “Experimentation Works”.
Another great case for applying multifactor DOE came from Kontsevaia and Berger in a study published by the International Journal of Business, Economics and Managemental**. To maximize impressions per social-media posts, they applied a fractional two-level design on 6 factors in 16 runs varying:
A. Type of Day/Day of the week: Weekend (Sat, Sun) vs Workday (Thu, Fri)
B. Social Media Channel: LinkedIn vs Twitter
C. Image present: No vs Yes
D. Time of Day: Afternoon (3-6pm) vs Morning (7-10am)
E. Length of Message: Long (at least 70 characters) vs Short (under 70 characters)
F. Hashtag present: No vs Yes
The multifactor marketing test revealed the choice of channel for maximum impressions to be highly dependent on posts going out on weekends versus workdays. This valuable insight on a two-factor interaction (AB) would never have been revealed by a simple OFAT split.
Design-Expert® software makes multifactor business experiments like this very easy for non-statisticians to design, analyze and optimize for greatly increased returns. Aided by Stat-Ease you can put DOE to work for your enterprise and make a big hit career-wise.
*“Building a Culture of Experimentation”, Stefan Thomke, March-April, 2020.
**“Analyzing Factors Affecting the Success of Social Media Posts for B2B Networks: A Fractional-Factorial Design Approach”, August, 2020.
Magic of multifactor testing revealed by fun physics experiment
If you haven't discovered Mark Anderson's Stats Made Easy blog yet, check it out! Mark offers a wry look at all things statistical and/or scientific from an engineering perspective. You will find posts on topics as varied as nature, science, sports, politics, and DOE. His latest post, Magic of multifactor testing, involves a fun DOE with bouncy balls.
The first article follows the setup of Mark's DOE. At the bottom of Part 1, click on the Related Links tab to find Part 2 (Results) and Part 3 (Data and Details)
That’s a Wrap!
The 2020 Online DOE Summit was a remarkable success! If you missed any of it, read on!
We just wrapped up our 2020 Online DOE Summit. What a successful summit. A group of influential speakers kicked off the discussion of design of experiments (DOE). Hundreds of attendees logged in to each talk and soaked up that knowledge. Thank you to everyone who participated.
We created the summit because of the COVID-19 pandemic. Originally scheduled for the middle of June, our 8th European DOE Meeting was canceled in January. So, after thinking about it for a bit, we decided to move the meeting online. This would be the only way to have a meeting for a while. Plus, the cost to the audience would be zero.
All the speakers who agreed to speak at the European meeting agreed to make the move to a virtual event. A schedule was set-up. We gave it a new name. We sent emails to everyone with dates. The 2020 Online DOE Summit was born.
Our first group of presentations consisted of a kickoff talk, three keynotes, and a tutorial. Many of these talks revolved around current directions in DOE. Even though DOE has been around for decades, it is an evolving practice with new techniques and advice coming up all the time. Each speaker discussed broad concepts in design of experiments.
[Click on the title of the talk for a video recording of the presentation.]
Kickoff: Know the SCOR for Multifactor Strategy of Experimentation
Mark Anderson: Principal of Stat-Ease, Inc.
Talk Topic: Laying out a strategy for multifactor design of experiments
Keynote: My Lifelong Journey with DOE
Pat Whitcomb: Founding Principal of Stat-Ease, Inc.
Talk topic: Pat explores his lifetime of design of experiments with a view to the future
Keynote: Some Experiences in Modern Experimental Design
Marcus Perry: Editor in Chief, Quality Engineering; Professor of Statistics, The University of Alabama
Talk topic: Handling non-standard situations in today’s DOE environment
Keynote: Innovative Mixture-Process Models
Geoff Vining: Professor of Statistics, Virginia Tech
Talk Topic: An overview of KCV designs that limit runs in experiments involving both mixture components and process variables
Tutorial: Strategies for Sequential Experimentation
Martin Bezener: Director of Research & Development, Stat-Ease, Inc.
Talk Topic: This presentation explores how it may be more efficient to divide an experiment into smaller pieces. Learn how to use resources in a smarter, more adaptive manner.
In the second week of the summit, we had a separate set of talks. Each one detailed real-world experiments. Presenters discussed the actual experiments they had worked on, and how they used DOE in each case.
Simultaneous and Quick Determination of Two Ingredients Concentrations in a Solution Using a UV-Vis Spectroscopy Chemometric Model
Samd Guizani: Process Scientist, Ferring International Center
Use of DOE for 3D Printer Ink Formulation Development
Uri Zadok: Senior Research Chemist, Stratasys
Using Experimental Design to Optimize the Surfactant Package Properties of a Metalworking Cleaner
Mathijs Uljé: Development Chemist, Quaker Houghton
Optimizing Multi-Step Processes with DoE – A Cryopreservation Protocol for Plant Cells as a Case
Johannes Buyel: Head of Department of Bioprocess Engineering, Aachen University
In all, this was a great summit. The presenters were spot on with the current state of DOE, whether in modern concepts or real-life experiments. The audience took away many useful ideas and practices. It was a classic case of making lemonade from lemons.
Thanks all!