Stat-Ease Blog

Categories
Greg's DOE Adventure: What is Design of Experiments (DOE)?
Hi there. I’m Greg. I’m starting a trip. This is an educational journey through the concept of design of experiments (DOE). I’m doing this to better understand the company I work for (Stat-Ease), the product we create (Design-Expert® software), and the people we sell it to (industrial experimenters). I will be learning as much as I can on this topic, then I’ll write about it. So, hopefully, you can learn along with me. If you have any comments or questions, please feel free to comment at the bottom.
So, off we go. First things first.
What exactly is design of experiments (DOE)?
When I first decided to do this, I went to Wikipedia to see what they said about DOE. No help there.
“The design of experiments (DOE, DOX, or experimental design) is the design of any task that aims to describe or explain the variation of information under conditions that are hypothesized to reflect the variation.” –Wikipedia
The what now?
That’s not what I would call a clearly conveyed message. After some more research, I have compiled this ‘definition’ of DOE:
Design of experiments (DOE), at its core, is a systematic method used to find cause-and-effect relationships. So, as you are running a process, DOE determines how changes in the inputs to that process change the output.
Obviously, that works for me since I wrote it. But does it work for you?
So, conceptually I’m off and running. But why do we need ‘designed experiments’? After all, isn’t all experimentation about combining some inputs, measuring the outputs, and looking at what happened?
The key words above are ‘systematic method’. Turns out, if we stick to statistical concepts we can get a lot more out of our experiments. That is what I’m here for. Understanding these ‘concepts’ within this ‘systematic method’ and how this is advantageous.
Well, off I go on my journey!
Correlation vs. causality
Recently, Stat-Ease Founding Principal, Pat Whitcomb, was interviewed to get his thoughts on design of experiments (DOE) and industrial analytics. It was very interesting, especially to this relative newbie to DOE. One passage really jumped out at me:
“Industrial analytics is all about getting meaning from data. Data is speaking and analytics is the listening device, but you need a hearing aid to distinguish correlation from causality. According to Pat Whitcomb, design of experiments (DOE) is exactly that. ‘Even though you have tons of data, you still have unanswered questions. You need to find the drivers, and then use them to advance the process in the desired direction. You need to be able to see what is truly important and what is not,’ says Pat Whitcomb, Stat-Ease founder and DOE expert. ‘Correlations between data may lead you to assume something and lead you on a wrong path. Design of experiments is about testing if a controlled change of input makes a difference in output. The method allows you to ask questions of your process and get a scientific answer. Having established a specific causality, you have a perfect point to use data, modelling and analytics to improve, secure and optimize the process.’"
It was the line ‘distinguish correlation from causality’ that got me thinking. It’s a powerful difference, one that most people don’t understand.
As I was mulling over this topic, I got into my car to drive home and played one of the podcasts I listen to regularly. It happened to be an interview with psychologist Dr. Fjola Helgadottir and her research into social media and mental health. As you may know, there has been a lot of attention paid to depression and social media use. When she brought up the concept of correlation and causality it naturally caught my attention. (And no, let’s not get into Jung’s concept of Synchronicity and whether this was a meaningful coincidence or not.)
The interesting thing that Dr. Helgadottir brought up was the correlation between social media and depression. That correlation is misunderstood by the general population as causality. She went on to say that recent research has not shown any causality between the two but has shown that people who are depressed are more likely to use social media more than other people. So there is a correlation between social media and depression, but one does not cause the other.
So, back to Pat’s comments. The data is speaking. We all need a listening device to tell us what it’s saying. For those of you in the world of industrial experimentation, experimental design can be that device that differentiates the correlations from the causality.
Design of Experiments (DOE): The Secret Weapon in Medical Device Design
“Multifactor testing via design of experiments (DOE) is the secret weapon for medical-device developers,” says Stat-Ease Principal Mark Anderson, lead author of the DOE and RSM Simplified series*. “They tend to keep their success to themselves to keep their competitive edge, but one story, that we can share, documents how a multinational manufacturer doubled their production rate while halving the variation of critical-to-quality performance. That’s powerful stuff!”
The case study that Mark is referring to can be found here: RSM for Med Devices.
Stat-Ease has guided many manufacturers in the medical device industry in the streamlining of their products and processes. Now, we have put that experience together into one place, the Designed Experiments for Medical Devices workshop.
In this one-of-a-kind workshop, learn how to optimize your medical device or process. Our DOE experts will show you how to use Design-Expert® software to help you save money or time while ensuring the quality of your product. We welcome scientists, engineers, and technical professionals working in this field, as well as organizations and institutions that devote most of their efforts to research, development, technology transfer, or commercialization of medical devices. Throughout this course you will get hands-on experience while using cases that come directly from this industry.
During a fast-paced two days, explore the use of fractional factorial designs for the screening and characterization of products or processes. Also see how to achieve top performance via response surface designs and multiple response optimization. Practice applying all these DOE tools while working through cases involving medical device design, pacemaker lead stress testing, and typical processes that may be used in the testing or production of these devices such as seal strength, soldering, dimensional analysis, and more.
For dates, location, cost, and more information about this workshop, visit: www.statease.com/training/workshops/class-demd-adin.html
About Stat-Ease and DOE
Based in Minneapolis, Stat-Ease has been a leading provider of design of experiments (DOE) software, training, and consulting since its founding in 1982. Using these powerful statistical tools, industrial experimenters can greatly accelerate the pace of process and product development, manufacturing troubleshooting and overall quality improvement. Via its multifactor testing methods, DOE quickly leads users to the elusive sweet spot where all requirements are met at minimal cost. The key to DOE is that by varying many factors, not just one, simultaneously, it enables breakthrough discoveries of previously unknown synergisms.
* DOE Simplified is a comprehensive introductory text on design of experiments
RSM Simplified is a simple and straight forward approach to response surface methods
Mixture Design of Experiments (DOE) to the Rescue!
So, you formulate products. Yes, you, in the industry of making beverages, chemicals, cosmetics, concrete, food, flavorings, metal alloys, pharmaceuticals, paints, plastics, paper, rubber, and so forth.
You also need to optimize that formulation—quickly. Mixture design of experiments (DOE) to the rescue! “Wait, what?” you ask.
When creating a formulation, you can use mixture DOE to model the blend in the form of a mathematical equation. It also allows you to show the effect each component has on the measured responses, both by itself and in combination with the other components.
This model then leads you to the optimal composition, or “sweet spot”, based on your desired outcome. And mixture design does this fast.
"Yeah, OK," you say. "It's going to take me months to learn how to do that. So, no thanks."
We have software that will do it for you, and a 3-day workshop that shows you how to use it. Not months, 3 days. We get it. You're not a statistician, you don't have the time to learn all the ins and outs of the theory. You just need to get to the information. We'll help you get there.
Ready to know more? Good! Download this white paper that illustrates how mixture design works and how Design-Expert® software will help you.
Ready to know even more? Head over to our Mixture Design workshop webpage and register now. This hands-on workshop will show you how Design-Expert® software can be used to design and analyze mixture experiments. The software provides the power for the generation of optimal designs, as well as sophisticated graphical outputs such as trace plots. You will learn how these methods work and what to look for. No statistical background needed!
If you have any questions regarding the workshop, email us at workshops@statease.com.
Four Questions that Define Which DOE is Right for You
Do you ever stare at the broad array of DOE choices and wonder where to start? Which design is going to provide you with the information needed to solve your problem? I’ve boiled this down to a few key questions. Each of them may trigger more in-depth conversation, but the answers are key to driving your design decisions.
- What is the purpose of your experiment? Typical purposes are screening, characterization, and optimization. The screening design will help identify main effects (it’s important to choose a design that will estimate main effects separately from two-factor interactions (2FI)). Characterization designs will estimate 2FI’s and give you the option to add center points to detect curvature. Optimization designs generally estimate non-linear, or quadratic effects. (See the blog “A Winning Strategy for Experimenters”.)
- Are your factors actually components in a formulation? This leads you to a mixture design. Consider this question – if you double all the components in the process, will the response be the same? If yes, then only mixture designs will properly account for the dependencies in the system. (Check out the Formulation Simplified textbook.)
- Do you have any Hard-to-Change factors? An example is temperature – it’s hard to randomly vary the temp setting higher and lower due to the time required to stabilize the process. If you were planning to sort your DOE runs manually to make it easier to run the experiment, then you likely have a hard-to-change factor. In this case, a split-plot design will give a more appropriate analysis.
- Are your factors all numeric, or all categoric, or some of each? Multilevel categoric designs work better with categoric factors that are set at more than 2 levels. A final option: optimal designs are highly flexible and can usually meet your needs for all factor types and require only minimal runs.
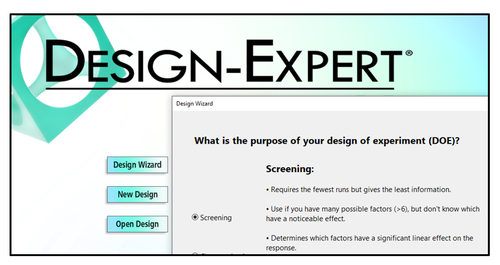
These questions, along with your budget for number of runs, will guide your decisions regarding what type of information is important to your business, and what type of factors you are using in the experiment. Conveniently, the Design Wizard in Design-Expert® software (pictured left) asks these questions, guiding you through the decision-making process, ultimately leading you to a recommended starting design.
Give it a whirl – Happy Experimenting!