Stat-Ease Blog

Categories
Ask An Expert: Jay Davies
Next in our 40th anniversary “Ask an Expert” blog series is John "Jay" Davies, who's an absolute rock star when it comes to teaching and implementing DOE. He's lent us his expertise before - see this talk from our 2022 Online DOE Summit - and he shared an anecdote with our statistical experts about how he approaches switching to DOE methods when working with new groups in the Army. He kindly agreed to let us publish it as part of this series.
For the past 14 years, I’ve been a Research Physicist with the U.S. Army DEVCOM Chemical Biological Center at Aberdeen Proving Grounds, MD as a member of the Decontamination Sciences Branch, which specializes in developing techniques/chemistries to neutralize chemical warfare agents. I’m dedicated to applied statistical analysis ranging from multi-laboratory precision studies to design of experiments (DOE). The Decontamination Sciences Branch has been integrating DOE methods into many of their chemical agent decontamination research programs.
I’m happy to report that the DOE methods here at the Chemical Biological Center are really catching on. I collaborated on 24 DOEs from 2014 through 2021. Then, in 2021-22, we completed 26 DOEs across 10 different programs. I’ve been doing a lot of mixture-process DOEs with the Bio Sciences groups for synthetic biology and bio manufacturing applications, and once the other groups saw the information that we were getting from just a single day’s worth of data, they too wanted to try DOE.
Lately, I’ve changed the formula that I use for the initial consultations when visiting a group that has expressed an interest in DOE but has never used DOE before. Previously we’d go right into their project, and I’d tell them how we might construct a DOE for their application. However, I’ve found that it’s too much of a culture shock if we go right into talking about what a DOE for their application might look like. Instead, especially if I’m working with a group that has no DOE experience at all, I now devote about 1 hour to discuss DOE methods in general before we even mention their actual application. In this discussion, I reveal the major differences that they are going to see with a DOE, which are:
- We’re not going to replicate every sample, we may even have zero exact replication.
- We’re not going to test every possible combination of factors.
- Sample sizes are going to be 70% to 95% smaller than what they are used to doing.
- We are not going to change “one factor at a time”, in fact we’ll be changing all factors at once.
- The designs might look chaotic, but they are strategically created to contain a hidden orthogonal structure, along with hidden replication, that is not apparent.
- You will see that many of the DOE samples contain factor combinations that don’t seem to make sense. This is because each sample is not designed as a stand-alone shot at optimization. Rather, the samples cumulatively are working in concert to tease out the influences of each factor. This will let us fit a predictive model that we will then use to predict the optimal settings of factors.
Recently, I was following this format with a group that had never used DOE before. We had a great back-and-forth dialog as I went through the bullets above and explained a bit about each point. They asked many questions and were really following along. Then, after about an hour we got into their application and I just sketched out a prototype quadratic mixture-process DOE that I thought would give them a good idea of what the initial DOE might look like, with 30 samples in total. I then went over what some simulated outputs for the DOE generated prediction model might look like. At this point one of them stopped me and with a very perplexed look on his face, said “hold on, hold on…wait a minute here. Are you telling us that if we run just those 30 samples, we would be able to predict the optimal formulation and the optimal process setting for this system?“
This scientist had been following along, asking questions and really absorbing the information in the past hour as we walked through the DOE basics, but I could see that at that moment things were just sinking in. He realized the ramifications of what we had just discussed – typically, this group might have had to run several hundreds of samples to characterize similar systems, but with DOE they would only need about 30 samples. I responded to his question saying, “Yes that’s exactly what I’m telling you. We’ve run dozens of these mixture-process DOEs, many of them much more complex than this system, and they do work.” This individual, a mid-career researcher, then responded, “How is it possible that we have not heard of this stuff before?” I told him, “I can’t give you a good answer to that one.”
And there you have it! Let us know if you want to talk about saving time & money with DOE: our statistical experts and first-in-class software make it easier than ever.
DISTRIBUTION STATEMENT A. Approved for Public Release: Distribution is Unlimited
Randomization Done Right
Randomization is essential for success with planned experimentation (DOE) to protect factor effects against bias by lurking variables. For example, consider the 8-run, two-level factorial design shown in Table 1. It lays out the low (−) and high (+) coded levels of each factor in standard, not random, order. Notice that factor C changes level only once throughout the experiment—first being set at the low (minus) level for four runs, followed by the remaining four runs set at the high (plus) level. Now, let’s say that the humidity in the room increases throughout the day—affecting the measured response. Since the DOE runs are not randomized, the change in humidity biases the calculated effect of the non-randomized factor C. Therefore, the effect of factor C includes the humidity change – it is no longer purely due to the change from low to high. This will cause analysis problems!
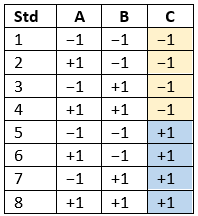
Table 1: Standard order of 8-run design
Randomization itself presents some problems. For example, one possible random order is the classic standard layout, which, as you now know, does not protect against time-related effects. If this unlikely pattern, or other non-desirable patterns are seen, then you should re-randomize the runs to reduce the possibility of bias from lurking variables.
Randomizing center points or other replicates
Replicates, such as center points, are used to collect information on the pure error of the system. To optimize the validity of this information, center points should be spaced out over the experimental run order. Random order may inadvertently place replicates in sequential order. This requires manual intervention by the researcher to break up or separate the repeated runs so that each run is completed independently of the matching run.
In both Design-Expert® software and Stat-Ease 360 you can re-randomize by right-clicking on the Run column header and selecting Randomize, as shown in Figure 1. You can also simply edit the Run order and swap two runs by changing the run numbers manually. This is often the easiest method when you want to separate center points, for example.
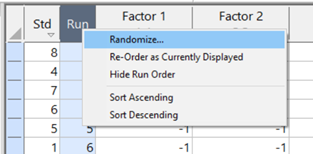
Figure 1: Right-click to Randomize
When Randomization Doesn’t Work
While randomization is ideal statistically, sometimes it is cumbersome in practice. For instance, temperature can take a very long time to change, so completely randomizing the runs may cause the experiment to go way beyond the time budget. In this case, researchers look for ways to reduce the complete randomization of the design.
I want to highlight a common DOE mistake. An incorrect way to restrict the randomization is to use blocks. Blocking is a statistical technique that groups the experimental runs to eliminate a potential source of variation from the data analysis. A common blocking factor is “day”, setting the block groups to eliminate day-to-day variation. Although this is a form of restricting randomization, if you block on an experimental factor like temperature, then statistically the block (temperature) effect will be removed from the analysis. Any interaction effect with that block will also be removed. The removal of this key effect very likely destroys the entire analysis! Blocking is not a useful method for restricting the randomization of a factor that is being studied in the experiment. For more information on why you would block, see “Blocking: Mowing the Grass in Your Experimental Backyard”.
If factor changes need to be restricted (not fully randomized), then building a split-plot design is the best way to go. A split-plot design takes into account the hard-to-change versus easy-to-change factors in a restricted randomization test plan. Perfect! The associated analysis properly assesses the differences in variation between these two groups of factors and provides the correct effect evaluation. The statistical analysis is a bit more complex, but good DOE software will handle it easily. Split-plot designs are a more complex topic, but commonly used in today’s experimental practices. Learn more about split-plot designs in this YouTube video: Split Plot Pros and Cons – Dealing with a Hard-to-Change Factor.
Wrapping up
Randomization is essential for valid and unbiased factor effect calculations, which is central to effective design of experiments analysis. It is up to the experimenter to ensure that the randomization of the experimental runs meets the DOE goals. Manual intervention may be required to separate any replicated points, such as center points. If complete randomization is not possible from a practical standpoint, build a split-plot design that statistically accounts for those restrictions.