Stat-Ease Blog

Categories
Mastering mixture modeling
Mixture models (also known as "Scheffé," after the inventor) differ from standard polynomials by their lack of intercept and squared terms. For example, most of us learned about quadratic models in high school and/or college math classes, such as this one for two factors:
These models are extremely useful for optimizing processes via response surface methods (RSM) such as central composite designs (CCDs).
Mixture models look different. For example, consider this non-linear blending model for the melting point (Y) of copper (X₁) and gold (X₂) derived from a statistically designed mixture experiment*:
As you can see, this equation, set up to work with components coded on a 0 to 1 scale, does not include an intercept (ß₀) or squared terms (X₁², X₂²). However, it works quite well for predicting the behavior of a two-component mixture. The first-order coefficients, 1043 and 1072, are quite simple to interpret—these fitted values quantify the measured** melting points in degrees C for copper and gold, respectively. The difference of 29 characterizes the main-component effect (copper 29 degrees higher than gold).
The second-order coefficient of 536 is a bit trickier to interpret. It being negative characterizes the counterintuitive (other than for metallurgists) nonlinear depression of the melting point at a 50/50 composition of the metals. But be careful when quantifying the reduction in the melting: It is far less than you might think. Figure 1 tells the story.
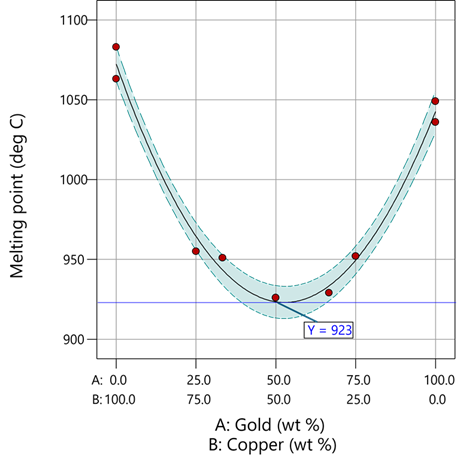
Figure 1: Response surface for melting point of copper versus gold
First off, notice that the left side—100% copper—is higher than the right side—100% gold. This is caused by the main-component effect. Then observe the big dip in the middle created by a significant, second-order impact from non-linear blending. Because of this, the melting point reaches a minimum of 923 degrees C at and just beyond the 50/50 blend point. This falls 134 degrees below the average melting point of 1057 degrees. Given the coefficient of -536 on the X₁X₂ term, you probably expected a much bigger reduction. It turns out 541 divided by 4 equals 134. This is not coincidental—at the 50/50 blend point the product of the coded values reaches a maximum of 0.25 (0.5 x 0.5), and thus the maximum deflection is one-fourth (1/4) of the coefficient.
If your head is spinning at this point, I advise you not to attempt to interpret coefficients of the mixture model beyond the main component effects and, if significant, only the sign of the second-order, non-linear blending term, that is, whether it is positive or negative. Then after validating your model via Stat-Ease software diagnostics, visualize the model performance via our program’s wonderful model graphics—trace plot, 2D contour, and 3D surface. Follow up by doing a numeric optimization to pinpoint an optimum blend that meets all your requirements.
However, if you would like to truly master mixture modeling, come to our next Fundamentals of Mixture DOE workshop.
* For the raw data, see Table 1-1 of A Primer on Mixture Design: What’s in it for Formulators. Due to a more precise fitting, the model coefficients shown in this blog differ slightly from those presented in the Primer.
** Keep in mind these are results from an experiment and thus subject to the accuracy and precision of the testing and the purity of the metals—the theoretical melting points for pure gold and copper are 1064 and 1085 degrees C, respectively.
Like the blog? Never miss a post - sign up for our blog post mailing list.
Hear Ye, Hear Ye: A Response Surface Method (RSM) Experiment on Sound Produces Surprising Results
A few years ago, while evaluating our training facility in Minneapolis, I came up with a fun experiment that demonstrates a great application of RSM for process optimization. It involves how sound travels to our students as a function of where they sit. The inspiration for this experiment came from a presentation by Tom Burns of Starkey Labs to our 5th European DOE User Meeting. As I reported in our September 2014 Stat-Teaser, Tom put RSM to good use for optimizing hearing aids.
Background
Classroom acoustics affect speech intelligibility and thus the quality of education. The sound intensity from a point source decays rapidly by distance according to the inverse square law. However, reflections and reverberations create variations by location for each student—some good (e.g., the Whispering Gallery at Chicago Museum of Science and Industry—a very delightful place to visit, preferably with young people in tow), but for others bad (e.g., echoing). Furthermore, it can be expected to change quite a bit from being empty versus fully occupied. (Our then-IT guy Mike, who moonlights as a sound-system tech, called these—the audience, that is—“meat baffles”.)
Sound is measured on a logarithmic scale called “decibels” (dB). The dBA adjusts for varying sensitivities of the human ear.
Frequency is another aspect of sound that must be taken into account for acoustics. According to Wikipedia, the typical adult male speaks at a fundamental frequency from 85 to 180 Hz. The range for a typical adult female is from 165 to 255 Hz.
Procedure

Stat-Ease training room at one of our old headquarters—sound test points spotted by yellow cups.
This experiment sampled sound on a 3x3 grid from left to right (L-R, coded -1 to +1) and front to back (F-B, -1 to +1)—see a picture of the training room above for location—according to a randomized RSM test plan. A quadratic model was fitted to the data, with its predictions then mapped to provide a picture of how sound travels in the classroom. The goal was to provide acoustics that deliver just enough loudness to those at the back without blasting the students sitting up front.
Using sticky notes as markers (labeled by coordinates), I laid out the grid in the Stat-Ease training room across the first 3 double-wide-table rows (4th row excluded) in two blocks:
- 2² factorial (square perimeter points) with 2 center points (CPs).
- Remainder of the 32 design (mid-points of edges) with 2 additional CPs.
I generated sound from the Online Tone Generator at 170 hertz—a frequency chosen to simulate voice at the overlap of male (lower) vs female ranges. Other settings were left at their defaults: mid-volume, sine wave. The sound was amplified by twin Dell 6-watt Harman-Kardon multimedia speakers, circa 1990s. They do not build them like this anymore 😉 These speakers reside on a counter up front—spaced about a foot apart. I measured sound intensity on the dBA scale with a GoerTek Digital Mini Sound Pressure Level Meter (~$18 via Amazon).
Results
I generated my experiment via the Response Surface tab in Design-Expert® software (this 3³ design shows up under "Miscellaneous" as Type "3-level factorial"). Via various manipulations of the layout (not too difficult), I divided the runs into the two blocks, within which I re-randomized the order. See the results tabulated below.
| Block | Run | Space Type | Coordinate (A: L-R) | Coordinate (B: F-B) | Sound (dBA) |
|---|---|---|---|---|---|
| 1 | 1 | Factorial | -1 | 1 | 70 |
| 1 | 2 | Center | 0 | 0 | 58 |
| 1 | 3 | Factorial | 1 | -1 | 73.3 |
| 1 | 4 | Factorial | 1 | 1 | 62 |
| 1 | 5 | Center | 0 | 0 | 58.3 |
| 1 | 6 | Factorial | -1 | -1 | 71.4 |
| 1 | 7 | Center | 0 | 0 | 58 |
| 2 | 8 | CentEdge | -1 | 0 | 64.5 |
| 2 | 9 | Center | 0 | 0 | 58.2 |
| 2 | 10 | CentEdge | 0 | 1 | 61.8 |
| 2 | 11 | CentEdge | 0 | -1 | 69.6 |
| 2 | 12 | Center | 0 | 0 | 57.5 |
| 2 | 13 | CentEdge | 1 | 0 | 60.5 |
Notice that the readings at the center are consistently lower than around the edge of the three-table space. So, not surprisingly, the factorial model based on block 1 exhibits significant curvature (p<0.0001). That leads to making use of the second block of runs to fill out the RSM design in order to fit the quadratic model. I was hoping things would play out like this to provide a teaching point in our DOESH class—the value of an iterative strategy of experimentation.
The 3D surface graph shown below illustrates the unexpected dampening (cancelling?) of sound at the middle of our Stat-Ease training room.
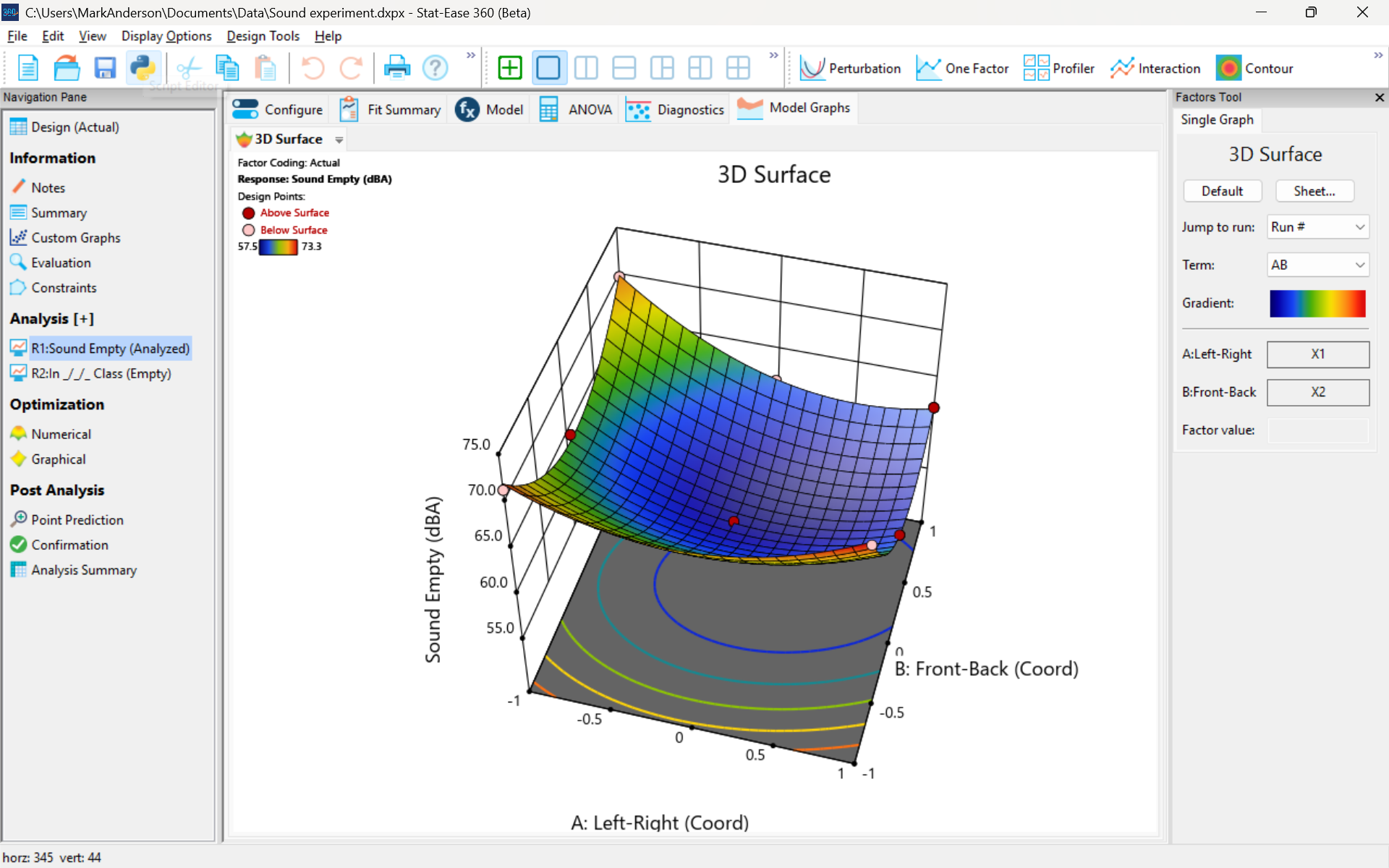
3D surface graph of sound by classroom coordinate.
Perhaps this sound ‘map’ is typical of most classrooms. I suppose that it could be counteracted by putting acoustic reflectors overhead. However, the minimum loudness of 57.4 (found via numeric optimization and flagged over the surface pictured) is very audible by my reckoning (having sat in that position when measuring the dBA). It falls within the green zone for OSHA’s decibel scale, as does the maximum of 73.6 dBA, so all is good.
What next
The results documented here came from an empty classroom. I would like to do it again with students (aka meat baffles) present. I wonder how that will affect the sound map. Of course, many other factors could be tested. For example, Rachel from our Front Office team suggested I try elevating the speakers. Another issue is the frequency of sound emitted. Furthermore, the oscillation can be varied—sine, square, triangle and sawtooth waves could be tried. Other types of speakers would surely make a big difference.
What else can you think of to experiment on for sound measurement? Let me know.
Like the blog? Never miss a post - sign up for our blog post mailing list.
October Publication Roundup
Here's the latest Publication Roundup! In these monthly posts, we'll feature recent papers that cited Design-Expert® or Stat-Ease® 360 software. Please submit your paper to us if you haven't seen it featured yet!
Featured Article
Green extraction of poplar type propolis: ultrasonic extraction parameters and optimization via response surface methodology
BMC Chemistry, 19, Article number: 266 (2025)
Authors: Milena Popova, Boryana Trusheva, Ralitsa Chimshirova, Hristo Petkov, Vassya Bankova
Mark's comments: A worthy application of response surface methods for optimizing an environmentally friendly process producing valuable bioactive compounds. I see they used Box-Behnken designs appropriately - good work!
Be sure to check out this important study, and the other research listed below!
More new publications from October
- Development and evaluation of a battery powered harvester for sustainable leafy vegetable cultivation
Scientific Reports, volume 15, Article number: 33812 (2025)
Authors: Kalluri Praveen, Yenikapalli Anil Kumar, Atul Kumar Shrivastava - Rutin/ZnO/mesoporous Silica-based Nano-hydrogel accelerated topical wound healing in albino mice via potential synergistic bioactive response
European Journal of Pharmaceutics and Biopharmaceutics, Volume 216, November 2025, 114875
Authors: Huma Butt, Haji Muhammad Shoaib Khan, Muhammad Sohail, Amina Izhar, Farhan Siddique, Maryam Bashir, Usman Aftab, Hasnain Shaukat - Production of improved Ethiopian Tej using mixed lactic acid bacteria and yeast starter cultures
Scientific Reports, volume 15, Article number: 33460 (2025)
Authors: Ketemaw Denekew, Fitsum Tigu, Dagim Jirata Birri, Mogessie Ashenafi, Feng-Yan Bai, Asnake Desalegn - Design and Optimization of Trastuzumab-Functionalized Nanolipid Carriers for Targeted Capecitabine Delivery: Anti-Cancer Effectiveness Evaluation in MCF-7 and SKBR3 Cells
International Journal of Nanomedicine, Volume 2025:20 Pages 12075—12102, 3 October 2025
Authors: Shubhashree Das, Bhabani Sankar Satapathy, Gurudutta Pattnaik, Sovan Pattanaik, Yahya Alhamhoom, Mohamed Rahamathulla, Mohammed Muqtader Ahmed, Ismail Pasha - **Design and test analysis of a rotary cutter device for root cutting of golden needle mushroom
Scientific Reports, volume 15, Article number: 37219 (2025)
Authors: Limin Xie, Yuxuan Gao, Zhiqiang Lin, Feifan He, Wenxin Duan, Dapeng Ye - Central composite design optimized fluorescent method using dual doped graphene quantum dots for lacosamide determination in biological samples
Scientific Reports, volume 15, Article number: 36507 (2025)
Authors: Ahmed Serag, Rami M. Alzhrani, Reem M. Alnemari, Maram H. Abduljabbar, Atiah H. Almalki - Innovation in functional bakery products: formulation and analysis of moringa-fortified millet cookies
Journal of Food Measurement and Characterization, Published: 17 October 2025
Authors: Anshu, Neeru & Ashwani Kumar - Improving the efficacy and targeting of letrozole for the control of breast cancer: in vitro and in vivo studies
Naunyn-Schmiedeberg's Archives of Pharmacology, Published: 13 October 2025
Authors: Shahira F. El Menshawe, Seif E. Ahmed, Amr Gamal Fouad, Amira H. Hassan - Optimization and Evaluation of Functionally Engineered Paliperidone Nanoemulsions for Improved Brain Delivery via Nasal Route
Molecular Pharmaceutics, Published October 7, 2025
Authors: Niserga D. Sawant, Pratima A. Tatke, Namita D. Desai - Innovative inhalable dry powder: nanoparticles loaded with Crizotinib for targeted lung cancer therapy
BMC Cancer, volume 25, Article number: 1526 (2025)
Authors: Faiza Naureen, Yasar Shah, Maqsood Ur Rehman, Fazli Nasir Fazli Nasir, Abdul Saboor Pirzada, Jamelah Saleh Al-Otaibi, Maria Daglia, Haroon Khan
September Publication Roundup
Here's the latest Publication Roundup! In these monthly posts, we'll feature recent papers that cited Design-Expert® or Stat-Ease® 360 software. Please submit your paper to us if you haven't seen it featured yet!
When choosing a featured article for each month, we try to make sure it's available for everyone to read. Unfortunately, none of this month's publications that met our standards are available to the public, so there's no featured article this month. We still recommend checking out the incredible research done by these teams, and congratulations to everyone for publishing!
New publications from September
- Evaluating the efficacy of nintedanib-invasomes as a therapy for non-small cell lung cancer
European Journal of Pharmaceutics and Biopharmaceutics, Volume 214, September 2025, 114810
Authors: Tamer Mohamed Mahmoud, Mohamed AbdElrahman, Mary Eskander Attia, Marwa M. Nagib, Amr Gamal Fouad, Amany Belal, Mohamed A.M. Ali, Nisreen Khalid Aref Albezrah, Shatha Hallal Al-Ziyadi, Sherif Faysal Abdelfattah Khalil, Mary Girgis Shahataa, Dina M. Mahmoud - Optimization of fermentation conditions for bioethanol production from oil palm trunk sap
Journal of the Indian Chemical Society, Volume 102, Issue 9, September 2025, 101943
Authors: Abdul Halim Norhazimah, Teh Ubaidah Noh, Siti Fatimah Mohd Noor - Microwave-assisted modification of a solid epoxy resin with a Peruvian oil
Progress in Organic Coatings, Volume 206, September 2025, 109333
Authors: Daniel Obregón, Antonella Hadzich, Lunjakorn Amornkitbamrung, G. Alexander Groß, Santiago Flores
Authors: Hüsniye Hande Aydın, Esra Karataş, Zeynep Şenyiğit, Hatice Yeşim Karasulu - Development of an innovative method of Salmonella Typhi biofilm quantification using tetrahydrofuran and response surface methodology
Microbial Pathogenesis, Volume 208, November 2025, 107992
Authors: Aditya Upadhyay, Dharm Pal, Awanish Kumar - Bauhinia monandra derived mesoporous activated carbon for the efficient adsorptive removal of phenol from wastewater
Scientific Reports volume 15, Article number: 31790 (2025)
Authors: Bhojaraja Mohan, Chikmagalur Raju Girish, Gautham Jeppu, Praveengouda Patil - Quality by Design-Driven Development, Greenness, and Whiteness Assessment of a Robust RP-HPLC Method for Simultaneous Quantification of Ellagic, Sinapic, and Syringic Acids
Separation Science Plus, Volume 8, Issue 9, September 2025, e70126
Authors: V. S. Mannur, Rahul Koli, Atith Muppayyanamath - Dissolution and separation of carbon dioxide in biohydrogen by monoethanolamine-based deep eutectic solvents
Journal of Chemical Technology and Biotechnology, Early View, 12 September 2025
Authors: Xiaokai Zhou, Yanyan Jing, Cunjie Li, Quanguo Zhang, Yameng Li, Tian Zhang, Kai Zhang - Strategic Implementation of Analytical Quality by Design in RP-HPLC Method Development for Andrographis paniculata and Chrysopogon zizanioides Extract-Loaded Phytosomes
Separation Science Plus, Volume 8, Issue 9, September 2025, e70125
Authors: Abisesh Muthusamy, Vinayak Mastiholimath, Darasaguppe R. Harish, Atith Muppayyanamath, Rahul Koli - Improving the bioavailability and therapeutic efficacy of valsartan for the control of cardiotoxicity-associated breast cancer
Journal of Drug Targeting, Published online: 29 Sep 2025
Authors: Mary Eskander Attia, Fatma I. Abo El-Ela, Saad M. Wali, Amr Gamal Fouad, Amany Belal, Fahad H. Baali, Nisreen Khalid Aref Albezrah, Mohammed S. Alharthi, Marwa M. Nagib
August Publication Roundup
Here's the latest Publication Roundup! In these monthly posts, we'll feature recent papers that cited Design-Expert® or Stat-Ease® 360 software. Please submit your paper to us if you haven't seen it featured yet!
Featured Article
Design and optimization of imageable microspheres for locoregional cancer therapy
Scientific Reports volume 15, Article number: 27487 (2025)
Authors: Brenna Kettlewell, Andrea Armstrong, Kirill Levin, Riad Salem, Edward Kim, Robert J. Lewandowski, Alexander Loizides, Robert J. Abraham, Daniel Boyd
Mark's comments: This is a great application of mixture design for optimal formulation of a medical-grade glass. The researchers used Stat-Ease software tools to improve the properties of microspheres to an extent that their use can be extended to cancers beyond the current application to those located in the liver. Well done!
Be sure to check out this important study, and the other research listed below!
More new publications from August
- Use of experimental design for screening and optimization of variables influencing photocatalytic degradation of pollutants in aqueous media: A review of chemometrics tools
Chemical Engineering Research and Design, Volume 220, August 2025, Pages 270-291
Authors: Pedro César Quero–Jiménez, Aracely Hernández–Ramírez, Jorge Luis Guzmán–Mar, Jorge Basilio de la Torre–López, Matheus Silva–Gigante, Laura Hinojosa–Reyes - Analytical Quality by Design-Based Stability-Indicating UHPLC Method for Determination of Inavolisib in Bulk and Formulation
Separation Science Plus, no. 8 (2025): 8, e70110
Authors: Ashwinkumar Matta, Raja Sundararajan - Enhanced anti-infective activities of sinapic acid through nebulization of lyophilized protransferosomes
Frontiers in Nanotechnology | Biomedical Nanotechnology, Volume 7 - 2025
Authors: Hani A. Alhadrami, Amr Gamal, Ngozi Amaeze, Ahmed M. Sayed, Mostafa E. Rateb, and Demiana M. Naguib - Optimizing Anti-Corrosive Properties of Polyester Powder Coatings Through Montmorillonite-Based Nanoclay Additive and Film Thickness
Corrosion and Materials Degradation, 2025, 6(3), 39
Authors: Marshall Shuai Yang, Chengqian Xian, Jian Chen, Yolanda Susanne Hedberg, James Joseph Noël - Regulatory mechanism and multi-index coordinated optimization of pipeline transportation performance of coarse-grained gangue slurry: Experimental and simulation investigation
Physics of Fluids 37, 073343 (2025)
Authors: Jianfei Xu (许健飞); Jixiong Zhang (张吉雄); Nan Zhou (周楠); Hao Yan (闫浩); Wenfu Zhou (周文福); Qian Chen (陈乾); Jiarun Chen (陈嘉润) - Optimization of clayey soil parameters with aeolian sand through response surface methodology and a desirability function
Scientific Reports volume 15, Article number: 30831 (2025)
Authors: Ghania Boukhatem, Messaouda Bencheikh, Mohammed Benzerara, Mehmet Serkan Kırgız, N. Nagaprasad, Krishnaraj Ramaswamy, Souhila Rehab-Bekkouche, R. Shanmugam - Development of electromagnetic drop weight release mechanism for human occupied vehicle
Scientific Reports volume 15, Article number: 30663 (2025)
Authors: Sathia Narayanan Dharmaraj, Karthikeyan Shanmugam, Jothi Chithiravel, Ramesh Sethuraman - Operating parameter optimization and experiment of spiral outer grooved wheel seed metering device based on discrete element method
Scientific Reports volume 15, Article number: 30762 (2025)
Authors: Tao Zhang, Xinglong Tang, Cong Dai, Guiying Ren - Parameter optimization of key components in seed-metering device for pre-cut seed stems of Pennisetum hydridum
Scientific Reports volume 15, Article number: 31318 (2025)
Authors: Chong Liu, Xiongfei Chen, Qiang Xiong, Muhua Liu, Junan Liu, Jiajia Yu, Peng Fang, Yihan Zhou, Chuanhong Zhan, Yao Xiao - Optimization of new and thermally aged natural monoesters blends for a sustainable management of power transformers
Industrial Crops and Products, Volume 235, 1 November 2025, 121741
Authors: Gerard Ombick Boyekong, Gabriel Ekemb, Emeric Tchamdjio Nkouetcha, Ghislain Mengata Mengounou, Adolphe Moukengue Imano