Greg's DOE Adventure - Factorial Design, Part 2
[Disclaimer: I’m not a statistician. Nor do I want you to think that I am. I am a marketing guy (with a few years of biochemistry lab experience) learning the basics of statistics, design of experiments (DOE) in particular. This series of blog posts is meant to be a light-hearted chronicle of my travels in the land of DOE, not be a text book for statistics. So please, take it as it is meant to be taken. Thanks!]
Keep your experiment planned, but random
When I wrote my introduction to factorial design (Greg’s DOE Adventure - Factorial Design, Part 1), there were a couple of points that I left out. I’ll amend that post here to talk about making sure your experiment is planned out yet random.
Wait. What?
You’ll see. Let me explain.
Getting organized
During the initial phase of an experiment, you should make sure that it is well planned out. First, think about the factors that affect the outcome of your experiment. You want to create a list that’s as all-encompassing as possible. Anything that may change the outcome, put on your list. Then pare it down into the ones that you know are going to be the biggest contributors.
Once you have done that, you can set the levels at which to run each factor. You want the low and high levels to be as far apart as possible. Not too low that you won’t see an effect (if your experiment is cooking something, don’t set the temperature so low that nothing happens). Not too high that it’s dangerous (as in cooking, you don’t want to burn your product).
Finally, you want to make sure your experiment is balanced when it comes to the factors in your experiment. Taking the cooking example above a little further, suppose you have three factors you are testing: time, temperature, and ingredient quality. Let’s also say that you are testing at two different levels: low and high (symbolized by minus and plus signs, respectively). We can write this out in a table:
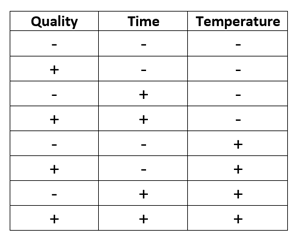
This table contains all the possible combinations of the three factors. It’s called an ‘orthogonal array’ because it’s balanced. Each column has the same number of pluses and minuses (4 in this case). This balance in the array allows all factors to be uncorrelated and independent from each other.
With these steps, you have ensured that your experiment is well planned out and balanced when looking at your factors.
Always randomize
At the start of this post, I said that an experiment should be planned out, yet random. Well we have the planned-out part, now let’s get into the random part.
In any experimentation, influence from external sources (variables you are not studying) should be kept to a minimum. One way to do this is randomizing your runs.
As an example, let’s look at the table above with the cooking example. Let’s say that it represents the order of how the experiment was run. So, all the low temperature runs were made together and then all the high ones together. This makes sense, right? Perform all the runs at one temperature before adjusting up to the next setting.
The problem is, what if there is an issue with your oven that causes the temperature to fluctuate more, early in the experiment and less later. This time-related issue introduces variation (bias) into your results that you didn’t know about.
To reduce the influence of this variable, randomize your run order. It may take more time adjusting your oven for every run, but it will remove that unwanted variation.
Temperature is a popular example to illustrate randomization. But this can be said of any factor that may have time-related problems. It could be warm-up time on a machine or the physical tiring of an operator. Randomization is used to guard against bias as much as you can when running an experiment.
Conclusions
Hopefully, you see now why I said to keep your experiments planned but random. It sounds like an oxymoron, but it’s not. Not in the way I’m talking about it here!