Understanding Lack of Fit: When to Worry
An analysis of variance (ANOVA) is often accompanied by a model-validation statistic called a lack of fit (LOF) test. A statistically significant LOF test often worries experimenters because it indicates that the model does not fit the data well. This article will provide experimenters a better understanding of this statistic and what could cause it to be significant.
The LOF formula is:
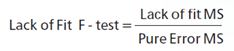
where MS = Mean Square. The numerator (“Lack of fit”) in this equation is the variation between the actual measurements and the values predicted by the model. The denominator (“Pure Error”) is the variation among any replicates. The variation between the replicates should be an estimate of the normal process variation of the system. Significant lack of fit means that the variation of the design points about their predicted values is much larger than the variation of the replicates about their mean values. Either the model doesn't predict well, or the runs replicate so well that their variance is small, or some combination of the two.
Case 1: The model doesn’t predict well
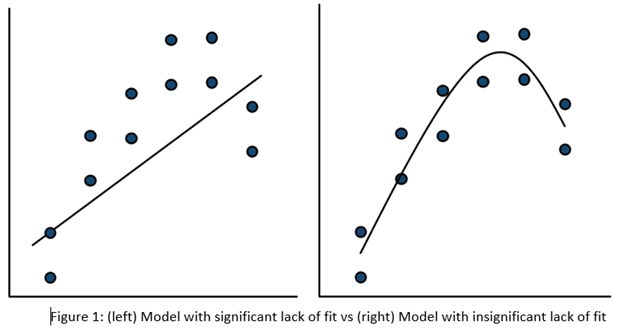
On the left side of Figure 1, a linear model is fit to the given set of points. Since the variation between the actual data and the fitted model is very large, this is likely going to result in a significant LOF test. The linear model is not a good fit to this set of data. On the right side, a quadratic model is now fit to the points and is likely to result in a non-significant LOF test. One potential solution to a significant lack of fit test is to fit a higher-order model.
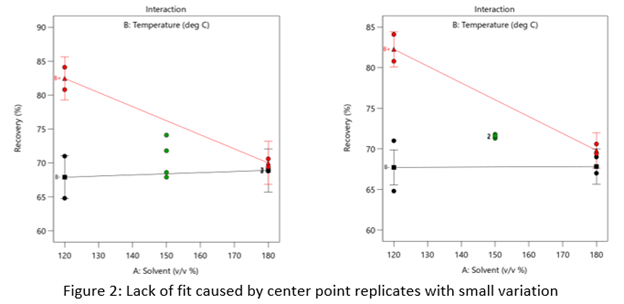
Case 2: The replicates have unusually low variability
Figure 2 (left) is an illustration of a data set that had a statistically significant factorial model, including some center points with variation that is similar to the variation between other design points and their predictions. Figure 2 (right) is the same data set with the center points having extremely small variation. They are so close together that they overlap. Although the predicted factorial model fits the model points well (providing the significant model fit), the differences between the actual data points are substantially greater than the differences between the center points. This is what triggers the significant LOF statistic. The center points are fitting better than the model points. Does this significant LOF require us to declare the model unusable? That remains to be seen as discussed below.
When there is significant lack of fit, check how the replicates were run— were they independent process conditions run from scratch, or were they simply replicated measurements on a single setup of that condition? Replicates that come from independent setups of the process are likely to contain more of the natural process variation. Look at the response measurements from the replicates and ask yourself if this amount of variation is similar to what you would normally expect from the process. If the “replicates" were run more like repeated measurements, it is likely that the pure error has been underestimated (making the LOF denominator artificially small). In this case, the lack of fit statistic is no longer a valid test and decisions about using the model will have to be made based on other statistical criteria.
If the replicates have been run correctly, then the significant LOF indicates that perhaps the model is not fitting all the design points well. Consider transformations (check the Box Cox diagnostic plot). Check for outliers. It may be that a higher-order model would fit the data better. In that case, the design probably needs to be augmented with more runs to estimate the additional terms.
If nothing can be done to improve the fit of the model, it may be necessary to use the model as is and then rely on confirmation runs to validate the experimental results. In this case, be alert to the possibility that the model may not be a very good predictor of the process in specific areas of the design space.